从源码理解 PostgreSQL buffer pool 设计
PostgreSQL(后面简称 PG) 是世界上最先进的开源关系型数据库,以功能强大、性能优越、开源包容著称,近年来收到众多开发者和公司的喜爱。基于 PG 数据库的衍生数据库众多,在各行各业发挥着举足轻重的作用。 而缓存管理对数据库的性能有着巨大的影响,本文抽丝剥茧,从源码角度剖析 PG buffer pool ,希望帮助读者一窥 PG 的实现。
PostgreSQL: The World’s Most Advanced Open Source Relational Database
前置知识
环境准备
安装数据库
# mac 上使用 brew 安装,其他系统参考官方文档
brew install postgresql@17
配置环境变量,根据电脑所用 shell 配置
echo 'export PATH="/opt/homebrew/opt/postgresql@17/bin:$PATH"' >> ~/.zshrc
下面源码,参考 working with git.
git clone https://git.postgresql.org/git/postgresql.git
PG 数据库目录
数据准备
创建测试数据库
createdb -O postgres -W daily_test
连接数据库
psql -U postgres -d daily_test
创建表
CREATE TABLE buffer_pool_test (
id INT NOT NULL,
name VARCHAR(255),
PRIMARY KEY (id)
);
数据库目录
数据库标志
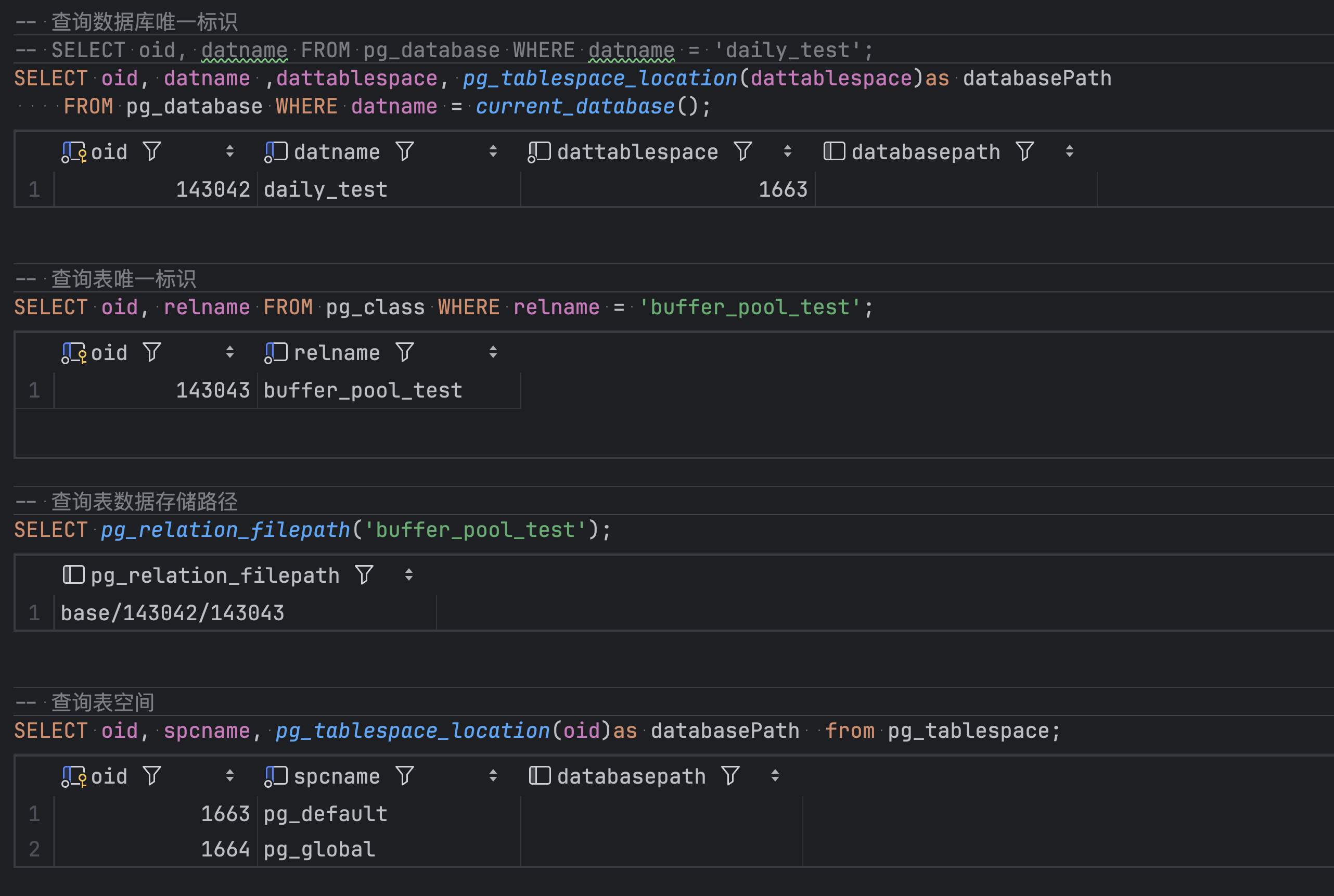
数据库存储路径
brew info postgresql@17
# Or, if you don't want/need a background service you can just run:
# LC_ALL="C" /opt/homebrew/opt/postgresql@17/bin/postgres -D /opt/homebrew/var/postgresql@17
查看数据库目录
➜ ~ ls /opt/homebrew/var/postgresql@17/base/143042 | grep 143043
# 143043
小结
PG 的数据库都存储在 $PG_DATA/base 下面。会为数据库创建目录,表创建文件,名称分别为数据库和表的 oid,通过系统表可以查询 oid 的值。
Buffer Tag
在 PG 中数据是以页(page)为单位组织的,简单来说,当需要修改某一条数据时,需要将数据所在的页从磁盘中读到内存中,然后修改内存中的页,修改完成后刷新到磁盘中。buffer pool 对内存的页进行管理,提供读取、写入、淘汰页的接口。
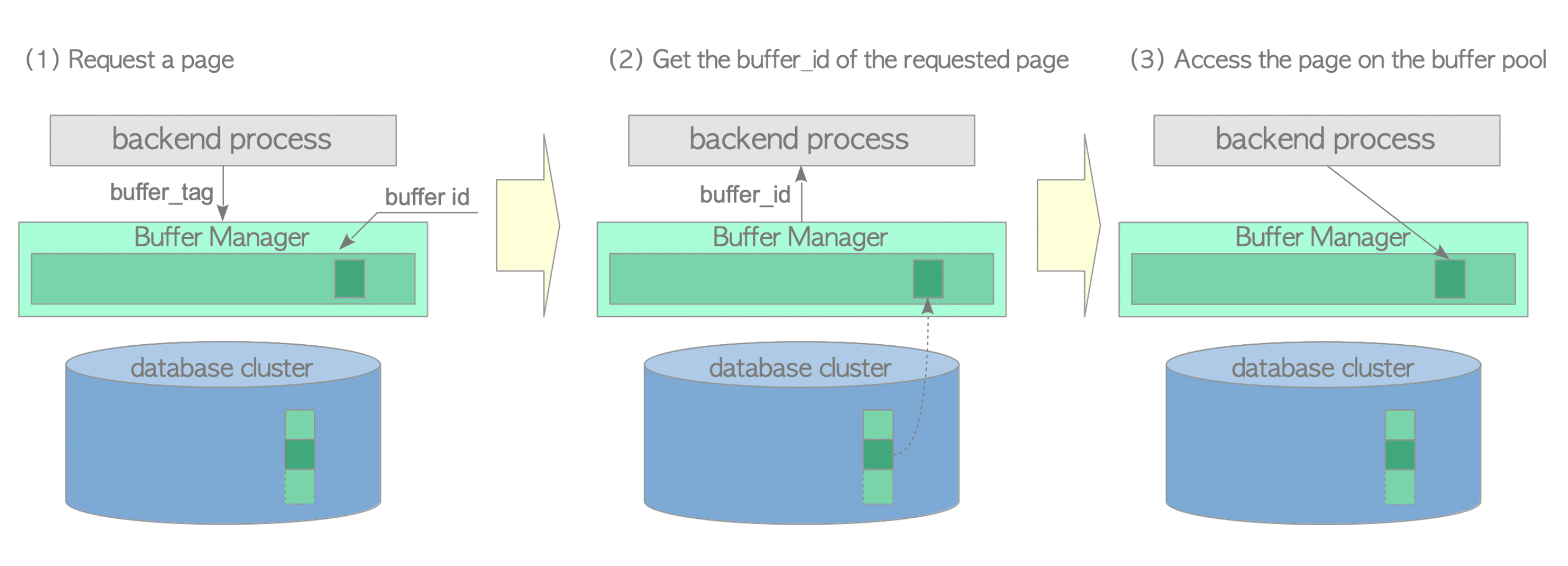
操作数据时,将磁盘中的数据加载到内存,进程需要知道数据所在的页,而页是由 buffer tag 唯一标识的。
typedef struct buftag
{
Oid spcOid; /* tablespace oid */
Oid dbOid; /* database oid */
RelFileNumber relNumber; /* relation file number */
ForkNumber forkNum; /* fork number */
BlockNumber blockNum; /* blknum relative to begin of reln */
} BufferTag
typedef unsigned int Oid;
typedef Oid RelFileNumber;
typedef enum ForkNumber
{
InvalidForkNumber = -1,
MAIN_FORKNUM = 0,
FSM_FORKNUM,
VISIBILITYMAP_FORKNUM,
INIT_FORKNUM,
} ForkNumber
typedef uint32 BlockNumber;
-
spcOid: 表空间,即数据库所在的目录。
在 pg 中所有数据的初始地址都是
$PG_DATA所在的目录,用户数据库默认所在的目录就是$PG_DATA/base,即下图中的pg_default。pg_global是全局数据存储,默认目录为$PG_DATA/global。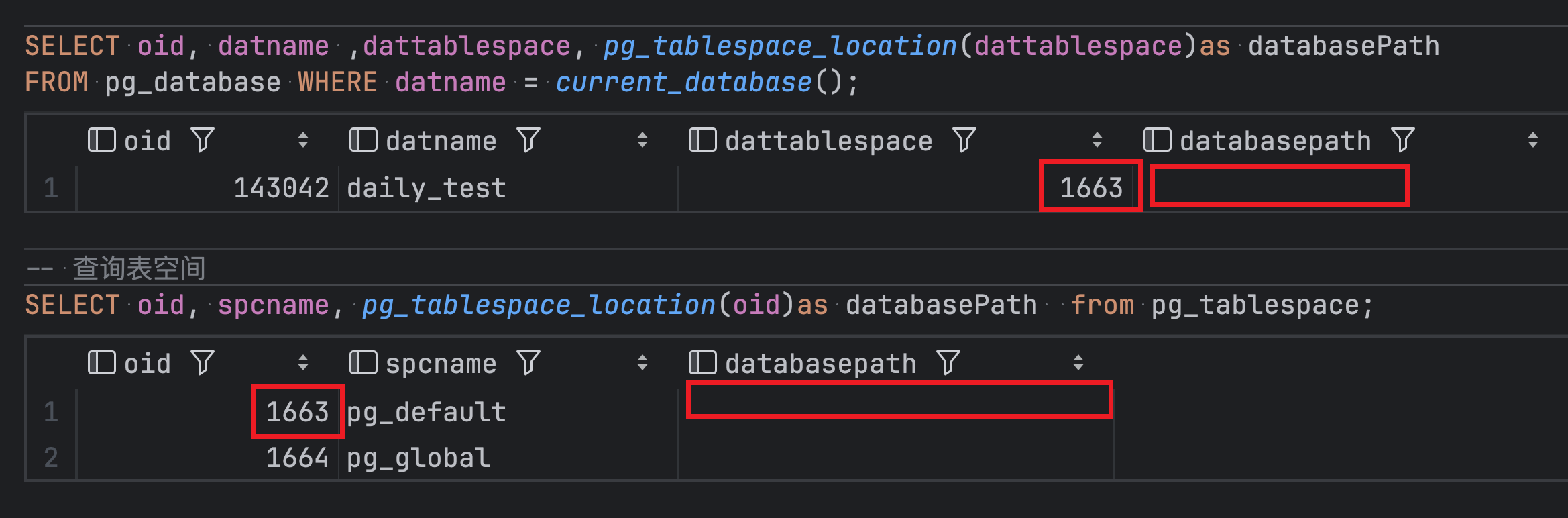
- dbOid 是数据库 id,本文所用数据库
daily_testoid 是 143042。 - relNumber 是表或者索引 oid,表和和索引在 pg 中称之为
relation。 - ForkNumber 是文件的类型,
- MAIN_FORKNUM, 表示实际存储表数据或者索引数据的文件。
- FSM_FORKNUM, 记录
MAIN_FORKNUM文件中每页空闲大小,pg 称为free space map。 - VISIBILITYMAP_FORKNUM, 记录
MAIN_FORKNUM文件中每页是否可见,在 ` Index-Only Scans会使用到,判断是否需要回表。vaccum` 操作也会使用此文件。索引没有此文件。
查看文件
准备数据
-- 插入十万条数据
INSERT INTO public.buffer_pool_test (id, name)
SELECT gs, 'name_' || gs
FROM generate_series(1, 100000) AS gs;
查询目录
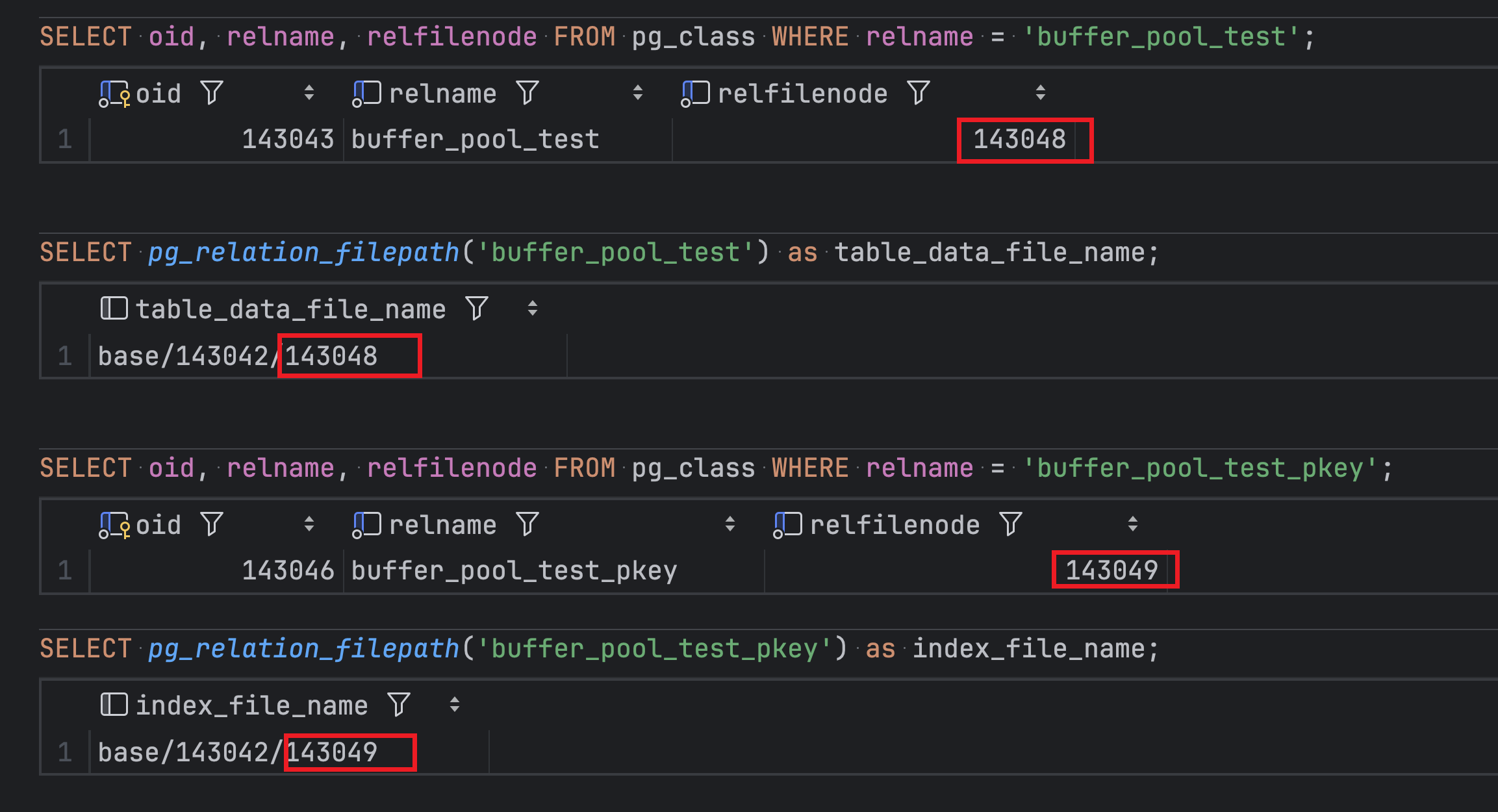
尽管 buffer_pool_test_pkey 是索引,在 pg 中也是 relation。表 pg_class 中 relfilenode 是实际的文件名。
查看文件

如果要查询表 buffer_pool_test 的第100页,buffer tag 为:
typedef struct buftag
{
Oid spcOid; /* tablespace oid */ 1663
Oid dbOid; /* database oid */ 143042
RelFileNumber relNumber; /* relation file number */ 143048
ForkNumber forkNum; /* fork number */ FSM_FORKNUM
BlockNumber blockNum; /* blknum relative to begin of reln */ 100
} BufferTag
buffer pool 结构
支撑 buffer pool 功能的是三个数据结构,三者之间通过 buffer id 关联起来。
- SharedBufHash, 底层实现为动态 hash 表,存储 buffer tag、hash value、buffer id。
- BufferDescriptors , 数组实现,存储 buffer id 、buffer descriptor,记录 buffer 的状态。
- BufferBlocks, 数组实现,存储 buffer id、page,这是实际存储 page 数据的结构。
SharedBufHash
SharedBufHash 本质是一个 hash 表,但是 pg 将其实现为两层结构。
void
InitBufTable(int size)
{
HASHCTL info;
/* BufferTag maps to Buffer */
info.keysize = sizeof(BufferTag);
info.entrysize = sizeof(BufferLookupEnt);
info.num_partitions = NUM_BUFFER_PARTITIONS;
SharedBufHash = ShmemInitHash("Shared Buffer Lookup Table", size, size, &info, ...); }
hash 表内部结构初始化,第一层是 dir,第二层是 seg,类比 Java 7 中 ConcurrentHashMap 的分段锁实现。
/* Initialize the hash header, plus a copy of the table name */
hashp = (HTAB *) DynaHashAlloc(sizeof(HTAB) + strlen(tabname) + 1)
hashp->dir = (HASHSEGMENT *) hashp->alloc(hctl->dsize * sizeof(HASHSEGMENT))
/* Allocate initial segments */
for (segp = hashp->dir; hctl->nsegs < nsegs; hctl->nsegs++, segp++) {
*segp = seg_alloc(hashp);
}
// seg_alloc
segp = (HASHSEGMENT) hashp->alloc(sizeof(HASHBUCKET) * hashp->ssize);
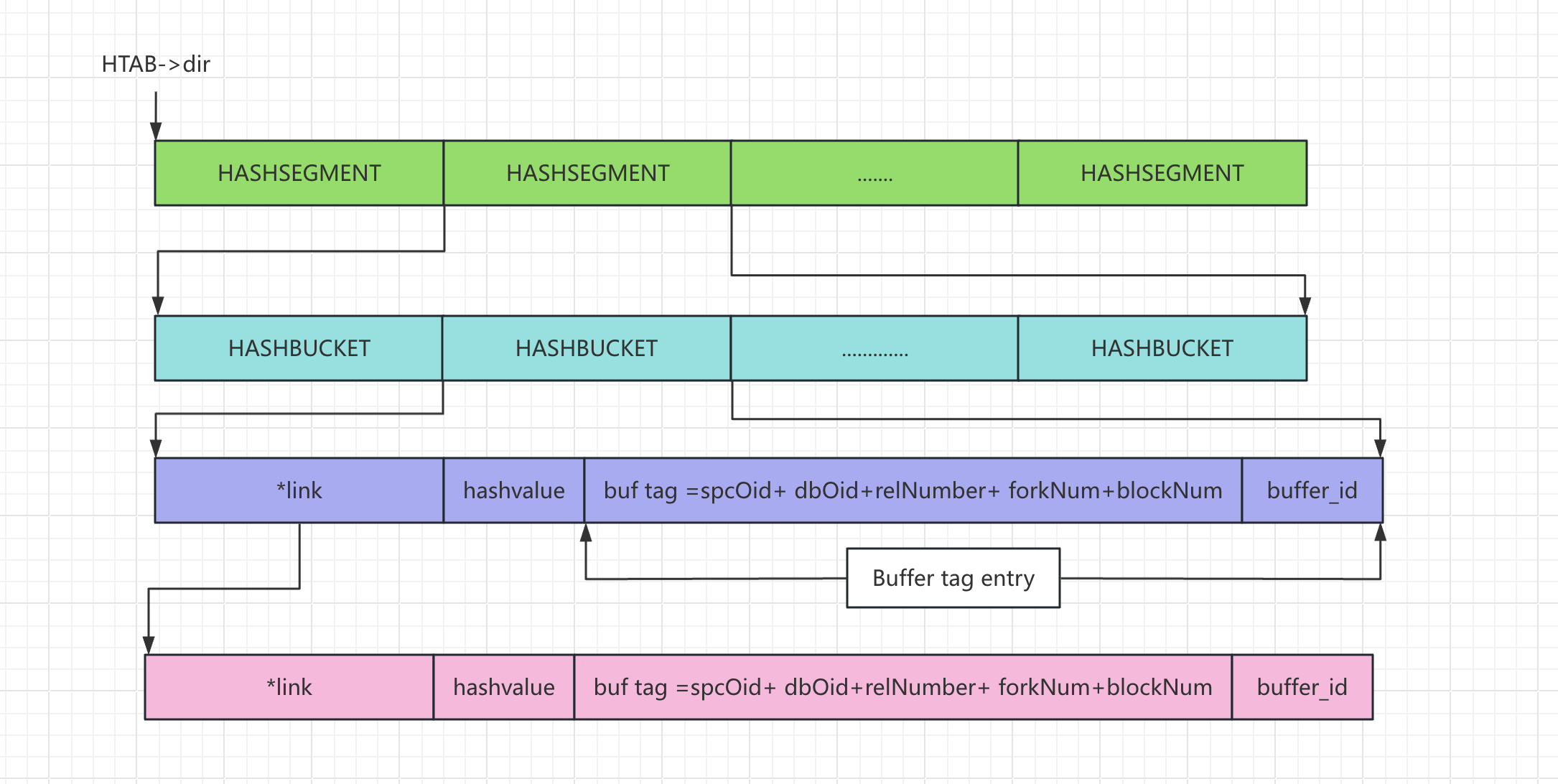
hash 表中元素为 HASHELEMENT ,link 使用拉链法解决 hash冲突,hashValue 记录 key 的 hash 值。
typedef struct HASHELEMENT
{
struct HASHELEMENT *link; /* link to next entry in same bucket */
uint32 hashvalue; /* hash function result for this entry */
} HASHELEMENT;
// 这里会实际存储业务数据
hash 值计算
uint32 get_hash_value(HTAB *hashp, const void *keyPtr) {
return hashp->hash(keyPtr, hashp->keysize);
}
通过 hash 值定义元素,先定位到 segp,然后定位到 bucketptr。
static inline uint32
hash_initial_lookup(HTAB *hashp, uint32 hashvalue, HASHBUCKET **bucketptr)
{
HASHHDR *hctl = hashp->hctl;
HASHSEGMENT segp;
long segment_num;
long segment_ndx;
uint32 bucket;
bucket = calc_bucket(hctl, hashvalue);
segment_num = bucket >> hashp->sshift;
segment_ndx = MOD(bucket, hashp->ssize);
segp = hashp->dir[segment_num];
*bucketptr = &segp[segment_ndx];
return bucket;
}
BufferDescriptors
BufferDescriptors 是一个数组,数组下标作为 buffer id,数组元素是 BufferDesc(BufferDescPadded),BufferDesc 是对 buffer 信息的封装。
BufferDescriptors = (BufferDescPadded *) ShmemInitStruct("Buffer Descriptors", NBuffers * sizeof(BufferDescPadded),
&foundDescs)
typedef union BufferDescPadded {
BufferDesc bufferdesc;
char pad[BUFFERDESC_PAD_TO_SIZE];
} BufferDescPadded;
typedef struct BufferDesc {
BufferTag tag; /* ID of page contained in buffer */
int buf_id; /* buffer's index number (from 0) */
/* state of the tag, containing flags, refcount and usagecount */
pg_atomic_uint32 state;
int wait_backend_pgprocno; /* backend of pin-count waiter */
int freeNext; /* link in freelist chain */
LWLock content_lock; /* to lock access to buffer contents */
} BufferDesc;
- freeNext, 记录下一个空闲 buffer 的下标。
- content_lock, 当前 buffer 的锁,
- state, 当前 buffer 使用的状态。
state 是无符号 32 位,下面是每个 bit 的含义,运行时使用位与移位等运算。
/*
* Buffer state is a single 32-bit variable where following data is combined.
*
* - 18 bits refcount
* - 4 bits usage count
* - 10 bits of flags
*/
#define BUF_REFCOUNT_ONE 1
#define BUF_REFCOUNT_MASK ((1U << 18) - 1)
#define BUF_USAGECOUNT_MASK 0x003C0000U
#define BUF_USAGECOUNT_ONE (1U << 18)
#define BUF_USAGECOUNT_SHIFT 18
#define BUF_FLAG_MASK 0xFFC00000
/* Get refcount and usagecount from buffer state */
#define BUF_STATE_GET_REFCOUNT(state) ((state) & BUF_REFCOUNT_MASK)
#define BUF_STATE_GET_USAGECOUNT(state) (((state) & BUF_USAGECOUNT_MASK) >> BUF_USAGECOUNT_SHIFT
#define BM_LOCKED (1U << 22) /* buffer header is locked */
#define BM_DIRTY (1U << 23) /* data needs writing */
#define BM_VALID (1U << 24) /* data is valid */
#define BM_TAG_VALID (1U << 25) /* tag is assigned */
#define BM_IO_IN_PROGRESS (1U << 26) /* read or write in progress */
#define BM_IO_ERROR (1U << 27) /* previous I/O failed */
#define BM_JUST_DIRTIED (1U << 28) /* dirtied since write started */
#define BM_PIN_COUNT_WAITER (1U << 29) /* have waiter for sole pin */
#define BM_CHECKPOINT_NEEDED (1U << 30) /* must write for checkpoint */
#define BM_PERMANENT (1U << 31) /* permanent buffer (not unlogged, * or init fork) */
初始化,注意 buffer id 就是数组的下标。
for (i = 0; i < NBuffers; i++)
{
BufferDesc *buf = GetBufferDescriptor(i);
ClearBufferTag(&buf->tag);
pg_atomic_init_u32(&buf->state, 0);
buf->wait_backend_pgprocno = INVALID_PROC_NUMBER;
buf->buf_id = i;
buf->freeNext = i + 1;
LWLockInitialize(BufferDescriptorGetContentLock(buf),
LWTRANCHE_BUFFER_CONTENT);
ConditionVariableInit(BufferDescriptorGetIOCV(buf));
}
BufferBlocks
BufferBlocks 是一个数组,数组下标是 buffer id,数组元素是一块 BLCKSZ 的连续内存,BLCKSZ 默认为 8096,即 8 k。
BufferBlocks = (char *) TYPEALIGN(PG_IO_ALIGN_SIZE, ShmemInitStruct("Buffer Blocks",
NBuffers * (Size) BLCKSZ + PG_IO_ALIGN_SIZE,
&foundBufs))
BufferAlloc
ReadBuffer_common 是通用的读取方法。将磁盘中的数据读取到内存 page 中分为两个步骤。
- 在 buffer pool 中找个空闲的 page。对应
StartReadBuffer -> StartReadBuffersImpl->PinBufferForBlock->BufferAlloc - 将磁盘数据读取到空闲 page 中。
ReadBuffer_common(elation rel, ForkNumber forkNum, BlockNumber blockNum, ...){
if (StartReadBuffer(&operation, &buffer,
blockNum, flags))
WaitReadBuffers(&operation);
return buffer
}
BufferAlloc 是寻找空闲 page 的核心逻辑。
BufTableLookup
- InitBufferTag 根据传入的数据构造 buffer tag。
- BufTableHashCode 计算 buffer tag 的 hash 值。
- BufTableLookup 根据 hash 值 和 buffer tag 在 SharedBufHash 查找。
InitBufferTag(&newTag, &smgr->smgr_rlocator.locator, forkNum, blockNum);
/* determine its hash code and partition lock ID */
newHash = BufTableHashCode(&newTag);
newPartitionLock = BufMappingPartitionLock(newHash);
/* see if the block is in the buffer pool already */
LWLockAcquire(newPartitionLock, LW_SHARED);
existing_buf_id = BufTableLookup(&newTag, newHash);
if (existing_buf_id >= 0){
buf = GetBufferDescriptor(existing_buf_id);
valid = PinBuffer(buf, strategy);
*foundPtr = true;
if(!valid) *foundPtr = false;
return buf;
}
- if (existing_buf_id >= 0) 如果找到则直接返回。
-
PinBuffer 增加 ref count 和 usage count。
buf_state += BUF_REFCOUNT_ONE buf_state += BUF_USAGECOUNT_ONE; pg_atomic_compare_exchange_u32(&buf->state, &old_buf_state, buf_state) - LWLockAcquire 和 LWLockRelease 是获取和释放分段锁。
StrategyGetBuffer
从 ring buffer 中获取缓冲区,ring buffer 专门为顺序扫描而使用的缓冲区,防止热点缓冲区被替换。
buf = GetBufferFromRing(strategy, buf_state);
唤醒 background writer 进程,将内存中的脏页刷盘,为后续寻找空闲页做准备,防止缓冲区耗尽。
SetLatch(&ProcGlobal->allProcs[bgwprocno].procLatch);
从空闲列表中获取空闲缓冲区
buf = GetBufferDescriptor(StrategyControl->firstFreeBuffer)
if (strategy != NULL)
AddBufferToRing(strategy, buf) //根据策略将 buffer 加入到 ring buffer。
根据 clock sweep 算法获取缓冲区,Clock Sweep 类似 LRU 算法,PostgreSQL 的 Clock Sweep 算法结合了简单性和高效性,在大多数负载下可以很好地管理缓冲区资源,同时避免了传统 LRU 算法的高开销问题。
对 buffer pool 中的缓冲区进行环形扫描,逐步减小扫描到缓冲区的 usage count ,当 ref count 和 usage count 都为 0 ,缓冲区可以用。
ref count 记录正在被其他进程访问的个数。usage count 记录从上次加载以来被访问的次数。
/* Nothing on the freelist, so run the "clock sweep" algorithm *
buf = GetBufferDescriptor(ClockSweepTick());
if (BUF_STATE_GET_REFCOUNT(local_buf_state) == 0) {
if (BUF_STATE_GET_USAGECOUNT(local_buf_state) != 0) {
local_buf_state -= BUF_USAGECOUNT_ONE;
}
else {
/* Found a usable buffer */
if (strategy != NULL)
AddBufferToRing(strategy, buf);
*buf_state = local_buf_state;
return buf; // 找到可用的缓冲区
}
}
GetVictimBuffer
使用 StrategyGetBuffer 获取到目标缓冲区后,需要做一些特殊处理。
如果获取的缓冲区是脏了,则需要刷新到磁盘中。
if (buf_state & BM_DIRTY) {
content_lock = BufferDescriptorGetContentLock(buf_hdr);
if (!LWLockConditionalAcquire(content_lock, LW_SHARED)) {
UnpinBuffer(buf_hdr);
goto again;
}
// 针对 strategy 做处理
/* OK, do the I/O */
FlushBuffer(buf_hdr, NULL, IOOBJECT_RELATION, io_context);
LWLockRelease(content_lock)
}
FlushBuffer 刷新数据到磁盘,事实上这里只是将数据刷到操作系统内核。
NOTE: this actually just passes the buffer contents to the kernel; the real write to disk won’t happen until the kernel feels like it. This is okay from our point of view since we can redo the changes from WAL. However, we will need to force the changes to disk via fsync before we can checkpoint WAL.
BufferAlloc
回到 BufferAlloc 方法,从结构 BufferDescriptors 找到目标 buffer 以后,需要将其加入到 SharedBufHash。
LWLockAcquire(newPartitionLock, LW_EXCLUSIVE);
existing_buf_id = BufTableInsert(&newTag, newHash, victim_buf_hdr->buf_id);
如果目标 buffer 已经被加入到 SharedBufHash,则需要释放目标 buffer ,操作已经存在的 buffer。
/**
* If somebody else inserted another buffer for the tag, we'll release the
* victim buffer we acquired and use the already inserted one.
*/
if (existing_buf_id >= 0){
UnpinBuffer(victim_buf_hdr);
StrategyFreeBuffer(victim_buf_hdr); //加入到空闲队列
//使用已经存在的buffer
existing_buf_hdr = GetBufferDescriptor(existing_buf_id);
valid = PinBuffer(existing_buf_hdr, strategy)
}
如果顺利将目标 buffer 加入到 SharedBufHash,则设置 buffer tag
victim_buf_hdr->tag = newTag
当 buffer id 在代码中传递的时候需要加 1,因为 0 被定义为无效的 buffer id,当实际获取 buffer desc 或者 page 时需要将传递的id 减 1.
/*
* Buffer identifiers.
*
* Zero is invalid, positive is the index of a shared buffer (1..NBuffers),
* negative is the index of a local buffer (-1 .. -NLocBuffer).
*/
typedef int Buffer;
#define InvalidBuffer 0
static inline Buffer
BufferDescriptorGetBuffer(const BufferDesc *bdesc) {
return (Buffer) (bdesc->buf_id + 1);
}
static inline Block
BufferGetBlock(Buffer buffer) {
return (Block) (BufferBlocks + ((Size) (buffer - 1)) * BLCKSZ);
}
WaitReadBuffers
构造批量读
如果需要读取多块数据,依次读取,并且如果块是相邻的话,会一起读取。
for (int i = 0; i < nblocks; ++i){
/* We found a buffer that we need to read in. */
io_buffers[0] = buffers[i];
io_pages[0] = BufferGetBlock(buffers[i]);
io_first_block = blocknum + i;
io_buffers_len = 1
while ((i + 1) < nblocks && WaitReadBuffersCanStartIO(buffers[i + 1], true)) {
/* Must be consecutive block numbers. */
//判断如果是相邻块
Assert(BufferGetBlockNumber(buffers[i + 1]) ==
BufferGetBlockNumber(buffers[i]) + 1);
io_buffers[io_buffers_len] = buffers[++i];
io_pages[io_buffers_len++] = BufferGetBlock(buffers[i]);
}
smgrreadv(operation->smgr, forknum, io_first_block, io_pages, io_buffers_len);
}
}
每次处理最大块数是 32
Buffer io_buffers[MAX_IO_COMBINE_LIMIT];
void *io_pages[MAX_IO_COMBINE_LIMIT];
#define MAX_IO_COMBINE_LIMIT PG_IOV_MAX
/* Define a reasonable maximum that is safe to use on the stack. */
#define PG_IOV_MAX Min(IOV_MAX, 32)
相邻块处理示意图

获取缓存区 page 首地址,是实际存在的 8k 内存。
BufferGetBlock(buffers[i]);
mdreadv
获取文件信息
MdfdVec v = _mdfd_getseg(reln, forknum, blocknum, false, EXTENSION_FAIL | EXTENSION_CREATE_RECOVERY);
typedef struct _MdfdVec
{
File mdfd_vfd; /* fd number in fd.c's pool */
BlockNumber mdfd_segno; /* segment number, from 0 */
} MdfdVec;
实际磁盘上读取的位置
seekpos = (off_t) BLCKSZ * (blocknum % ((BlockNumber) RELSEG_SIZE));
将文件信息、内存中 page 信息进行封装。
iovcnt = buffers_to_iovec(iov, buffers, nblocks_this_segment)
FileReadV
实际读取文件,将磁盘中的数据读取到内存中
nbytes = FileReadV(v->mdfd_vfd, iov, iovcnt, seekpos, WAIT_EVENT_DATA_FILE_READ)
returnCode = pg_preadv(vfdP->fd, iov, iovcnt, offset)
part = pg_pread(fd, iov[i].iov_base, iov[i].iov_len, offset);
pg_pread 申明为 pread 实际读取文件,函数申明为
ssize_t pread(int fd, void buf[.count], size_t count, off_t offset);
至此,PG 将文件中的数据加载进内存。
使用下面语句就可以获取 page
/*
* BufferGetPage
* Returns the page associated with a buffer.
*/
static inline Page
BufferGetPage(Buffer buffer)
{
return (Page) BufferGetBlock(buffer);
}
总结
本文从源码的角度深入剖析了 PostgreSQL 缓冲池的设计和实现。通过构建数据库环境,解析数据库目录和文件结构,详细讲解了缓冲池的核心数据结构(SharedBufHash、BufferDescriptors、BufferBlocks)及其在缓冲池管理中的作用。
在缓冲区分配流程中,我们分析了从定位页面 (BufferTag 的构造与查找)、缓存命中的处理到基于 Clock Sweep 算法实现缓存淘汰的完整逻辑,展现了 PostgreSQL 如何高效地管理内存中的页面,并结合分段锁与 ring buffer 等优化机制,避免缓存热点和资源竞争问题。
可以看到,PostgreSQL 的缓冲池设计兼顾了功能性与性能,既为数据库的高效读写提供了保障,又通过灵活的策略控制了内存资源的使用。这种设计不仅奠定了 PostgreSQL 作为开源数据库性能标杆的基础,也为我们学习数据库系统的实现提供了宝贵的参考。希望本文能帮助读者更加深入地理解 PostgreSQL 的实现,为探索数据库系统内部原理打开一扇窗。