源码理解 Java 对象创建
在 Java 的日常开发中,对象的创建是最常见的操作之一。然而,对于 JVM 如何解析 new 指令、分配内存并初始化对象,许多开发者知之甚少。深入理解对象的创建过程,可以帮助我们更好地优化代码性能、排查内存管理问题以及了解 JVM 的运行机制。
本文通过一个简单的代码示例,逐步深入到 JVM 的字节码、类加载器和内存分配的实现细节,解析了对象创建从 new 指令到对象初始化的全过程。同时,结合 G1 垃圾收集器的内存分配策略,对大对象和普通对象的分配逻辑进行了详细探讨,为读者揭示了 JVM 的内部实现原理。
创建对象
在 Java 中使用 new 关键字创建对象,代码如下。
public class ObjNewTest {
public static ObjNewTest getInstance() {
return new ObjNewTest();
}
}
通过 javap 命令查看字节码指令,可以看到 getInstance 方法被编译成多条指令。其中 new 指令的执行过程是本文的主要内容。
#7 = Class #8 // test/java/ObjNewTest
#8 = Utf8 test/java/ObjNewTest
#9 = Methodref #7.#3 // test/java/ObjNewTest."<init>":()V
public static test.java.ObjNewTest getInstance();
descriptor: ()Ltest/java/ObjNewTest;
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=0, args_size=0
0: new #7 // class test/java/ObjNewTest
3: dup
4: invokespecial #9 // Method "<init>":()V
7: areturn
指令 new #7 创建对象,对象的类型是 #7 指向 class,即 test/java/ObjNewTest。
类加载
在 JVM 中,类加载过程就是将二进制的字节码文件读入内存中转换成 Class 对象的过程,这个过程由 classLoader 来完成。由 Java 实现的类加载器都是继承于 java.lang.ClassLoader,调用 defineClass1 方法来实现类加载。
static native Class<?> defineClass1(ClassLoader loader, String name, byte[] b,
int off, int len...);
defineClass1 本地方法由下面方法实现。
JNI_ENTRY(jclass, jni_DefineClass(JNIEnv *env, const char *name, jobject loaderRef,
const jbyte *buf, jsize bufLen)) {
Klass* k = SystemDictionary::
resolve_from_stream(&st, class_name, class_loader, cl_info, CHECK_NULL);
}
在 c++ 代码层面,类加载的过程就是解析 buf 二进制数组,生成 Klass 对象的过程。
类加载器
在 JNI 中加载器loaderRef 是 jobject类型,需要将 Java object 转换成 C++ 定义的 oop。
Handle class_loader (THREAD, JNIHandles::resolve(loaderRef))
类加载器会被封装成 ClassLoaderData,它实际管理类加载器相关的数据,多个ClassLoaderData 组成 ClassLoaderDataGraph。
class ClassLoaderData {
// The instance of java/lang/ClassLoader associated with
// this ClassLoaderData
OopHandle _class_loader;
Klass* _class_loader_klass;
// Handles to constant pool arrays, Modules, etc, which
// have the same life cycle of the corresponding ClassLoader.
ChunkedHandleList _handles;
// The classes defined by the class loader.
Klass* volatile _klasses;
}
// List head of all class loader data.
ClassLoaderData* volatile ClassLoaderDataGraph::_head = nullptr;
类解析
KlassFactory::create_from_stream 是类解析和 Class 实例化的入口函数。
ClassFileParser 负责解析 Java 二进制流,构造 ClassFileParser::ClassFileParser 调用 ClassFileParser::parse_stream 解析。
比如解析魔数和版本号
const u4 magic = stream->get_u4_fast();
// Version numbers
_minor_version = stream->get_u2_fast();
_major_version = stream->get_u2_fast();
- parse_constant_pool: 解析常量池。
- parse_interfaces: 解析接口。
- parse_fields: 解析字段。
- parse_methods: 解析方法。
- parse_classfile_attributes: 属性和注解。
在方法解析的时候,会保存常量池的信息,方法执行的时候需要访问常量池。
Method* const m = Method::allocate(....);
m->set_constants(_cp); // ConstantPool* _cp;
常量池解析
常量池解析按照字节码文件的规则逐个解析常量池,着重看下对 class info 符号引用的解析。
switch (tag) {
case JVM_CONSTANT_Class : {
cfs->guarantee_more(3, CHECK); // name_index, tag/access_flags
const u2 name_index = cfs->get_u2_fast();
cp->klass_index_at_put(index, name_index);
break; ...... }
}
void klass_index_at_put(int cp_index, int name_index) {
tag_at_put(cp_index, JVM_CONSTANT_ClassIndex);
*int_at_addr(cp_index) = name_index;
}
class info 占用 3 个字节,第一个字节 tag = 7 表示类型,后连个字节叫做 name_index ,表示引用其他常量,即常量池中其他字符串。下面是前文例子中 class info 16进制表示。
00000030 69 74 3e 01 00 03 28 29 56【07 00 08】【01 00 14 74
00000040 65 73 74 2f 6a 61 76 61 2f 4f 62 6a 4e 65 77 54
00000050 65 73 74】0a 00 07 00 03 01 00 04 43 6f 64 65 01
0x07 表示 class info,0x0008 表示 name_index 引用第 8 个常量。后面接着就是第8个常量,
0x01 表示 UTF-8 编码的字符串,长度是 0x00 14,即 20,类容是如下:
74 65 73 74 2f 6a 61 76 61 2f 4f 62 6a 4e 65 77 54 65 73 74
t e s t / j a v a / O b j N e w T e s t
// test/java/ObjNewTest
进一步解析,将常量索引与其引用的字符串常量索引存起来。本例子中,
- cp_index = 7
- name_index = 8
- resolved_klass_index = 1
后文续会使用此信息
case JVM_CONSTANT_ClassIndex: {
const int class_index = cp->klass_index_at(index); //name_index
cp->unresolved_klass_at_put(index, class_index, num_klasses++);
break
}
void unresolved_klass_at_put(int cp_index, int name_index, int resolved_klass_index) {
*int_at_addr(cp_index) =
build_int_from_shorts((jushort)resolved_klass_index, (jushort)name_index);
}
InstanceKlass
首先创建 InstanceKlass 实例,然后填充数据,至此类加载完成。
InstanceKlass* const ik =
InstanceKlass::allocate_instance_klass(*this, CHECK_NULL);
fill_instance_klass(ik, changed_by_loadhook, cl_inst_info, CHECK_NULL);
parse_constant_pool(stream, cp, _orig_cp_size, CHECK)
InstanceKlass 与 ClassLoaderData 相互关联。
// Set name and CLD before adding to CLD
ik->set_class_loader_data(_loader_data);
_loader_data->add_class(ik, publicize);
将 Klass 加入到字典中,便于查询。
//define_instance_class->update_dictionary
dictionary->add_klass(current, name, k);
将 cpp 中的 Kclass 转换成 java 中的 Class
cls = (jclass)JNIHandles::make_local(THREAD, k->java_mirror());
对象长度
分配对象之前必须先计算对象的大小, class 文件解析完成就可以知道实例对象的大小了。
parse_stream(stream, CHECK); //解析 class 文件
//后置操作
post_process_parsed_stream(stream, _cp, CHECK);
构造对象内存布局,并且计算对象大小。
FieldLayoutBuilder lb(class_name(), super_klass(), _cp, /*_fields*/ _temp_field_info,
_parsed_annotations->is_contended(), _field_info);
//lb.build_layout()->compute_regular_layout()->epilogue()
_info->_instance_size = align_object_size(instance_end / wordSize);
将对象大小保存在 _layout_helper 。
InstanceKlass::InstanceKlass(const ClassFileParser& parser,...){
set_layout_helper(Klass::instance_layout_helper(parser.layout_size(), false));
}
jint ClassFileParser::layout_size() const {
return _field_info->_instance_size;
}
new 指令
当 JVM 执行 return new ObjNewTest() 代码时,对应执行下面的字节码,字节码中 new 指令为对象分配内存。
#7 = Class #8 // test/java/ObjNewTest
#8 = Utf8 test/java/ObjNewTest
#9 = Methodref #7.#3 // test/java/ObjNewTest."<init>":()V
public static test.java.ObjNewTest getInstance();
descriptor: ()Ltest/java/ObjNewTest;
Code:
stack=2, locals=0, args_size=0
0: new #7 // class test/java/ObjNewTest
3: dup
4: invokespecial #9 // Method "<init>":()V
7: areturn
根据 java byte code 指令集合 上述代码二进制是:
Offset: 0 1 2 3 4 5 6 7
Byte: 0xbb 00 07 0x59 0xb7 00 09 0xb0
new #7 dup invokespecial #9 areturn
也可以使用二进制工具查看文件内容,【】之间的内容是 getInstance 方法。
> hexdump -C ObjNewTest.class
...omit
00000100 00 00 00 00 00 08 【bb 00 07 59 b7 00 09 b0】 00 00
...omit
指令执行
new 指令编码定义。
//src/hotspot/share/interpreter/bytecodes.hpp
_new = 187, // 0xbb
bytecodeInterpreter.cpp CASE(_new): 语句中执行。
//src/hotspot/share/interpreter/zero/bytecodeInterpreter.cpp
CASE(_new):
u2 index = Bytes::get_Java_u2(pc+1);
CALL_VM(InterpreterRuntime::_new(THREAD, METHOD->constants(), index),
handle_exception);
pc 指向的是 0xbb的起始地址,pc+1 指向的是 0x0007的起始地址。Bytes::get_Java_u2(pc+1) 获取的是0x0007十进制值,即 index = 7。
METHOD 是当前正在执行的方法,即 getInstance(),METHOD->constants() 获取的是常量池。
#define METHOD istate->method()
定位 Klass
根据 cp_index,即 new #7 中的 7 在常量池中找到 name_index 和 resolved_klass_index,这两个值都是 KClass 初始化的时候设置的。
//-> klass_at -> klass_at_impl
CPKlassSlot klass_slot_at(int cp_index) const {
int value = *int_at_addr(cp_index);
int name_index = extract_high_short_from_int(value);
int resolved_klass_index = extract_low_short_from_int(value);
return CPKlassSlot(name_index, resolved_klass_index);
}
//前文设置代码:*int_at_addr(cp_index) =
//build_int_from_shorts((jushort)resolved_klass_index, (jushort)name_index);
如果常量池中已经保存了 KClass 实例,则直接返回。
// -> klass_at_impl
if (this_cp->tag_at(cp_index).is_klass()) {
Klass* klass = this_cp->resolved_klasses()->at(resolved_klass_index);
if (klass != nullptr) {
return klass;
} }
如果常量池中没有保存KClass 实例,则从全局字典中查找,并且保存到常量池中。
Symbol* name = this_cp->symbol_at(name_index);
Klass* k = SystemDictionary::resolve_or_fail(name, loader, true, THREAD);
Klass** adr = this_cp->resolved_klasses()->adr_at(resolved_klass_index);
Atomic::release_store(adr, k)
对象分配
创建对象需两个信息。
- 对象所占内存大小。
- 对象 KClass 指针,对象头有 klass 指针指向 KClass 实例。
instanceOop InstanceKlass::allocate_instance(TRAPS) {
size_t size = size_helper(); // Query before forming handle.
return (instanceOop)Universe::heap()->obj_allocate(this, size, CHECK_NULL);
}
oop MemAllocator::allocate() const {
oop obj = nullptr;
Allocation allocation(*this, &obj);
HeapWord* mem = mem_allocate(allocation);
if (mem != nullptr) {
obj = initialize(mem);
} else { obj = nullptr; }
return obj;
}
mem_allocate(allocation) 分配内存,initialize(mem) 初始化对象头。
首先对新分配的内存做清理填充,然后初始化对象,设置对象头和对象指针。
oop ObjAllocator::initialize(HeapWord* mem) const {
mem_clear(mem);
return finish(mem);
}
void MemAllocator::mem_clear(HeapWord* mem) const {
const size_t hs = oopDesc::header_size();
if (oopDesc::has_klass_gap()) {
oopDesc::set_klass_gap(mem, 0);
}
Copy::fill_to_aligned_words(mem + hs, _word_size - hs);
}
oop MemAllocator::finish(HeapWord* mem) const {
if (UseCompactObjectHeaders) {
oopDesc::release_set_mark(mem, _klass->prototype_header());
} else {
oopDesc::set_mark(mem, markWord::prototype());
oopDesc::release_set_klass(mem, _klass);
}
return cast_to_oop(mem);
}
static markWord prototype() {
return markWord( no_hash_in_place | no_lock_in_place );
}
内存分配最终会调用不同的垃圾收集器实现,负责内存分配与回收。本小节以 G1CollectedHeap 为例。
HeapWord* mem = Universe::heap()->mem_allocate(_word_size, ...);
HeapWord* G1CollectedHeap::mem_allocate(size_t word_size,
bool* gc_overhead_limit_was_exceeded) {
if (is_humongous(word_size)) {
return attempt_allocation_humongous(word_size);
}
size_t dummy = 0;
return attempt_allocation(word_size, word_size, &dummy);
}
大对象分配-内存充足
大对象判断
static bool is_humongous(size_t word_size) {
return word_size > _humongous_object_threshold_in_words;
}
//_humongous_object_threshold_in_words 初始化
_humongous_object_threshold_in_words = humongous_threshold_for(G1HeapRegion::GrainWords);
static size_t humongous_threshold_for(size_t region_size) {
return (region_size / 2); //region size 的一半
}
//G1HeapRegion::GrainWords 初始化
void G1HeapRegion::setup_heap_region_size(size_t max_heap_size) {
size_t region_size = G1HeapRegionSize;
GrainBytes = region_size
GrainWords = GrainBytes >> LogHeapWordSize;
}
尝试为大对象分配内存,从代码中循环可以看出只能分配成功。
- 直接分配成功。
- 执行 GC 后分配成功。
We will loop until
- a) we manage to successfully perform the allocation or
- b) successfully schedule a collection which fails to perform the allocation. Case b) is the only case when we’ll return null
HeapWord* result = nullptr;
for (uint try_count = 1; /* we'll return */; try_count++) {
{
size_t size_in_regions = humongous_obj_size_in_regions(word_size);
result = humongous_obj_allocate(word_size);
if(result!=nullptr) return result;//success
}
{
result = do_collection_pause(word_size, gc_count_before, &succeeded,
GCCause::_g1_humongous_allocation);
if (succeeded) return result; // success
}
ShouldNotReachHere();
return nullptr;
}
humongous_obj_size_in_regions(word_size); 计算大对象占用的 region 个数,大对象都是单独占用一个或多个 region。
free list
大对象分配内存实际上是找到一个或多个连续空闲的 region。 G1 首先尝试从空闲列表分配内存,失败时则先扩展堆大小再分配。成功时对分配到的 region 做初始化。
HeapWord* G1CollectedHeap::humongous_obj_allocate(size_t word_size) {
uint obj_regions = (uint) humongous_obj_size_in_regions(word_size);
G1HeapRegion* humongous_start = _hrm.allocate_humongous(obj_regions);
if (humongous_start == nullptr) {
humongous_start = _hrm.expand_and_allocate_humongous(obj_regions);
if (humongous_start != nullptr) {
} }
HeapWord* result = nullptr;
if (humongous_start != nullptr) {
result = humongous_obj_allocate_initialize_regions(humongous_start, obj_regions, word_size);
}
return result
}
当只需要一个空闲 region 时,时直接从空闲列表中移除一个 region 返回即可,移除逻辑就是双向列表的删除逻辑。
G1HeapRegion* G1HeapRegionManager::allocate_humongous(uint num_regions) {
// Special case a single region to avoid expensive search.
if (num_regions == 1) {
return allocate_free_region(G1HeapRegionType::Humongous, G1NUMA::AnyNodeIndex);
}
return allocate_humongous_from_free_list(num_regions);
}
G1HeapRegion* G1HeapRegionManager::allocate_free_region(...){
hr = _free_list.remove_region(from_head);
}
inline G1HeapRegion* G1FreeRegionList::remove_region(bool from_head) {
return remove_from_head_impl();
}
inline G1HeapRegion* G1FreeRegionList::remove_from_head_impl() {
G1HeapRegion* result = _head;
_head = result->next();
if (_head == nullptr) { _tail = nullptr; }
else { _head->set_prev(nullptr); }
result->set_next(nullptr);
return result;
}
下面是 G1 region 示意图。
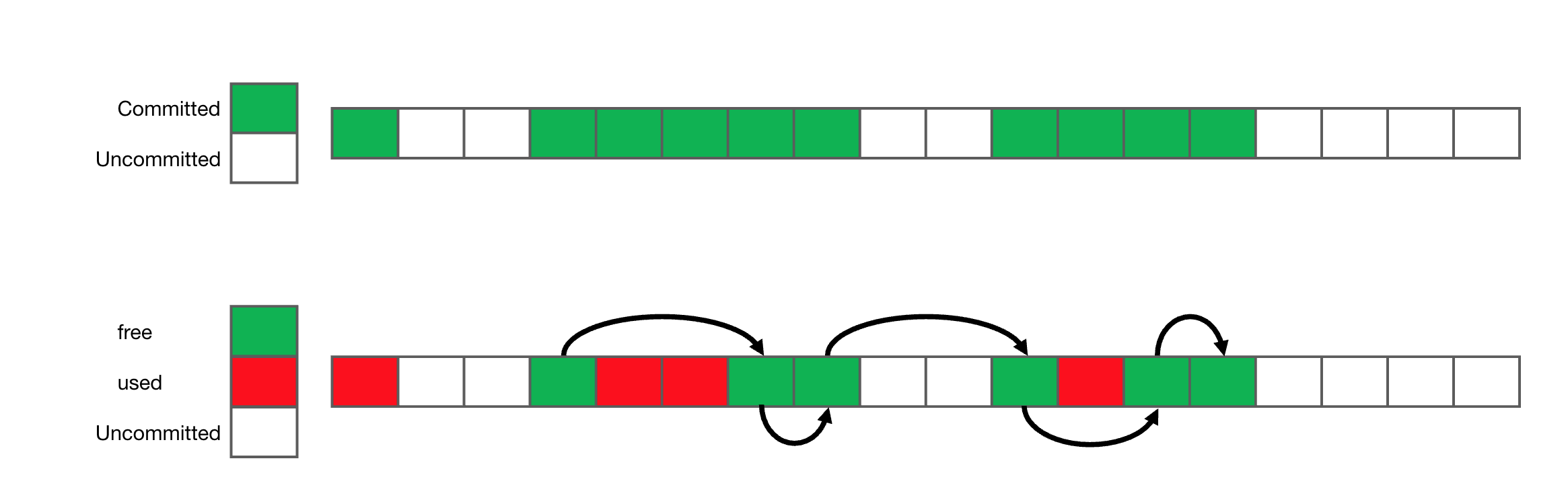
Committed Region 是指已经向操作系统申请了物理内存,可以随时使用,Uncommitted Region 则反之。Committed Region 对应的索引会在 _active 标记为 1。
// Each bit in this bitmap indicates that the corresponding region is active
// and available for allocation.
CHeapBitMap _active;
Committed Region 又分为 used Region 和 free region ,前者是实际在使用,分配了 Java 对象,后者没有被使用,并且被组织成一个 free list (绿色部分)。
当需要一个空闲 region 时,只需要在空闲列表中获取一个 region 即可。当需要多个相邻的空闲 region 时则需要查找,find_contiguous_in_free_list 函数就是这样的作用。
G1HeapRegion* G1HeapRegionManager::allocate_humongous_from_free_list(uint num_regions) {
uint candidate = find_contiguous_in_free_list(num_regions);
if (candidate == G1_NO_HRM_INDEX) {
return nullptr;
}
return allocate_free_regions_starting_at(candidate, num_regions);
}
uint G1HeapRegionManager::find_contiguous_in_free_list(uint num_regions) {
uint candidate = G1_NO_HRM_INDEX;
G1HeapRegionRange range(0,0);
do {
range = _committed_map.next_active_range(range.end());
candidate = find_contiguous_in_range(range.start(), range.end(), num_regions);
} while (candidate == G1_NO_HRM_INDEX && range.end() < reserved_length());
return candidate;
}
next_active_range 函数通过 _active 找到 Committed region ,它可能是一个也可能是多个连续的。
find_contiguous_in_range 在 Committed region 中找到连续的满足要求的 region,逻辑在简单注释。
uint G1HeapRegionManager::find_contiguous_in_range(uint start, uint end, uint num_regions) {
uint candidate = start; // First region in candidate sequence.
uint unchecked = candidate; // First unchecked region in candidate.
// While the candidate sequence fits in the range...
while (num_regions <= (end - candidate)) { //保证区间中 region 个数满足要求
// Walk backward over the regions for the current candidate.
for (uint i = candidate + num_regions - 1; true; --i) {
//首先检查最右(距离起始位置是 num_regions - 1)的region是否满足要求
if (is_available(i) && !at(i)->is_free()) {
// Region i can't be used, so restart with i+1 as the start
// of a new candidate sequence, and with the region after the
// old candidate sequence being the first unchecked region.
unchecked = candidate + num_regions;
candidate = i + 1; //不满足要求时:则需要将起始位置移动到最右不满足要求的位置 +1
break; //进行下一次 while 循环
} else if (i == unchecked) {
//说明 [unchecked, candidate + num_regions - 1] 都没有被使用。
//区间长度满足 num_regions ,说明找到连续的空闲 region 则退出。
// All regions of candidate sequence have passed check.
assert_contiguous_range(candidate, num_regions);
return candidate;
}
//当前 region 没有被使用进行下一次 for 循环
}
}
return G1_NO_HRM_INDEX;
}
allocate_free_regions_starting_at 从空闲列表中移除本次分配的 region 并返回本次分配连续 region 的起始 region 。
inline G1HeapRegion* G1HeapRegionManager::allocate_free_regions_starting_at(uint first, uint num_regions) {
G1HeapRegion* start = at(first);
_free_list.remove_starting_at(start, num_regions);
return start;
}
Uncommit region
从 Uncommit region 中分配内存,allocate_humongous_allow_expand 部分代码逻辑与 allocate_humongous_from_free_list 类似不赘述。
除此之外,expand_exact 对 Uncommit region 初始化,commit_regions 向操作系统申请内存。
G1HeapRegion* G1HeapRegionManager::allocate_humongous_allow_expand(uint num_regions) {
uint candidate = find_contiguous_allow_expand(num_regions);
if (candidate == G1_NO_HRM_INDEX) {
return nullptr;
}
expand_exact(candidate, num_regions, G1CollectedHeap::heap()->workers());
return allocate_free_regions_starting_at(candidate, num_regions);
}
humongous_obj_allocate_initialize_regions 方法记录一些原数据和统计数据。
HeapWord* new_obj = first_hr->bottom(); //对象的起始位置
Copy::fill_to_words(new_obj, oopDesc::header_size(), 0); //零值填充对象头
// Next, update the metadata for the regions.
set_humongous_metadata(first_hr, num_regions, word_size, true)
size_t used = byte_size(first_hr->bottom(), last_hr->top()); //统计使用的字节数
increase_used(used);
_humongous_set.add(hr); //将 region 添加到集合
first_hr->set_starts_humongous(obj_top, words_fillable); //标记起始region
hr->set_continues_humongous(first_hr);// 标记 continues region
大对象分配-需要 GC
当内存不足时先进行 GC ,然后再进行分配,GC 逻辑和分配逻辑封装在 VM_G1CollectForAllocation中,最终还是使用 humongous_obj_allocate 函数进行分配。
HeapWord* G1CollectedHeap::do_collection_pause(size_t word_size, uint gc_count_before,
bool* succeeded, GCCause::Cause gc_cause) {
VM_G1CollectForAllocation op(word_size, gc_count_before, gc_cause);
VMThread::execute(&op);
HeapWord* result = op.result();
bool ret_succeeded = op.prologue_succeeded() && op.gc_succeeded();
*succeeded = ret_succeeded;
return result;
}
void VM_G1CollectForAllocation::doit(){
// Try a partial collection of some kind.
_gc_succeeded = g1h->do_collection_pause_at_safepoint();
if (_word_size > 0) {
// An allocation had been requested. Do it, eventually trying a stronger
// kind of GC.
_result = g1h->satisfy_failed_allocation(_word_size, &_gc_succeeded);
}else{
//触发 GC 的原因可能是堆管理策略、外部请求或清理任务,与具体的分配无关。
}
}
普通对象
MutatorAllocRegion
首先从正在使用中的 region 中分配内存。
attempt_retained_allocation 和 attempt_allocation 区别在于前者从_retained_alloc_region 分配,而后者从 _alloc_region,这个过程是不需要加锁的。
inline HeapWord* G1Allocator::attempt_allocation(size_t min_word_size,
size_t desired_word_size,
size_t* actual_word_size) {
uint node_index = current_node_index();
HeapWord* result = mutator_alloc_region(node_index)->attempt_retained_allocation(min_word_size, desired_word_size, actual_word_size);
if (result != nullptr) { return result; }
return mutator_alloc_region(node_index)->attempt_allocation(min_word_size, desired_word_size, actual_word_size);
}
当 _alloc_region 不满足某次分配要求时,会执行 retire 方法,可能会赋值给 _retained_alloc_region,增加 region 内存利用率。
size_t MutatorAllocRegion::retire(bool fill_up) {
size_t waste = 0;
trace("retiring");
G1HeapRegion* current_region = get();
if (current_region != nullptr) {
if (should_retain(current_region)) {
if (_retained_alloc_region != nullptr) {
//先让 _retained_alloc_region retire
waste = retire_internal(_retained_alloc_region, true);
}
//将current_region 赋值给 _retained_alloc_region
_retained_alloc_region = current_region;
} else {
waste = retire_internal(current_region, fill_up);
}
reset_alloc_region();
}
return waste;
}
从 region 中分配对象内存
inline HeapWord* G1HeapRegion::par_allocate(size_t min_word_size, size_t desired_word_size, size_t* actual_word_size) {
do {
HeapWord* obj = top();
size_t available = pointer_delta(end(), obj);
size_t want_to_allocate = MIN2(available, desired_word_size);
if (want_to_allocate >= min_word_size) {
HeapWord* new_top = obj + want_to_allocate;
HeapWord* result = Atomic::cmpxchg(&_top, obj, new_top);
if (result == obj) {
*actual_word_size = want_to_allocate;
return obj;
}
} else { return nullptr; }
} while (true);
}
分配新 region
当常规方法无法分配成功时, 执行 attempt_allocation_slow 函数,首先获取锁,然后执行三个步骤。
attempt_allocation_locked尝试分配新的 region。do_collection_pause执行 GC。attempt_allocation再次尝试分配。
HeapWord* G1CollectedHeap::attempt_allocation_slow(size_t word_size){
MutexLocker x(Heap_lock);
result = _allocator->attempt_allocation_locked(word_size);
result = do_collection_pause(word_size, gc_count_before, &succeeded, GCCause::_g1_inc_collection_pause);
result = _allocator->attempt_allocation(word_size, word_size, &dummy)
}
retire “退休” _alloc_region,根据条件赋值给 _retained_alloc_region。 retire 重要一步就是将 region 加入到回收集中 ` collection_set()->add_eden_region(alloc_region)`。
inline HeapWord* G1AllocRegion::attempt_allocation_using_new_region(size_t min_word_size, size_t desired_word_size, size_t* actual_word_size) {
retire(true /* fill_up */);
HeapWord* result = new_alloc_region_and_allocate(desired_word_size);
if (result != nullptr) {
*actual_word_size = desired_word_size;
return result;
}
return nullptr;
}
HeapWord* G1AllocRegion::new_alloc_region_and_allocate(size_t word_size) {
G1HeapRegion* new_alloc_region = allocate_new_region(word_size);
if (new_alloc_region != nullptr) {
new_alloc_region->reset_pre_dummy_top();
HeapWord* result = new_alloc_region->allocate(word_size);
OrderAccess::storestore();
update_alloc_region(new_alloc_region);
return result;
} else { return nullptr; }
ShouldNotReachHere();
}
G1HeapRegion* MutatorAllocRegion::allocate_new_region(size_t word_size) {
return _g1h->new_mutator_alloc_region(word_size, _node_index);
}
new_mutator_alloc_region 首先使用 should_allocate_mutator_region 判断年轻代 region 的数量。
G1HeapRegion* G1CollectedHeap::new_mutator_alloc_region(size_t word_size,
uint node_index) {
assert_heap_locked_or_at_safepoint(true /* should_be_vm_thread */);
bool should_allocate = policy()->should_allocate_mutator_region();
if (should_allocate) {
G1HeapRegion* new_alloc_region = new_region(word_size, G1HeapRegionType::Eden, false /* do_expand */, node_index);
if (new_alloc_region != nullptr) { }
}
return nullptr;
}
bool G1Policy::should_allocate_mutator_region() const {
uint young_list_length = _g1h->young_regions_count();
return young_list_length < young_list_target_length();
}
allocate_free_region 从空闲列表中获取空闲 region,失败时使用 expand_single_region 从 OS 中分配新的 region,然后再次使用 allocate_free_region 。
G1HeapRegion* G1CollectedHeap::new_region(size_t word_size, G1HeapRegionType type,
bool do_expand, uint node_index) {
G1HeapRegion* res = _hrm.allocate_free_region(type, node_index);
if (res == nullptr && do_expand) {
if (expand_single_region(node_index)) {
res = _hrm.allocate_free_region(type, node_index);
} }
return res;
}
触发 GC
无论是大对象还是普通对象内存分配不足时都要执行 GC, GC 和分配操作封装成 VM_G1CollectForAllocation,委托 VMThread 线程触发 GC。
result = do_collection_pause(word_size, gc_count_before,
&succeeded, GCCause::_g1_humongous_allocation); // 大对象
result = do_collection_pause(word_size, gc_count_before,
&succeeded, GCCause::_g1_inc_collection_pause); // 普通对象
HeapWord* G1CollectedHeap::do_collection_pause(size_t word_size, uint gc_count_before,
bool* succeeded, GCCause::Cause gc_cause) {
assert_heap_not_locked_and_not_at_safepoint();
VM_G1CollectForAllocation op(word_size, gc_count_before, gc_cause);
VMThread::execute(&op);
HeapWord* result = op.result();
bool ret_succeeded = op.prologue_succeeded() && op.gc_succeeded();
*succeeded = ret_succeeded;
return result;
}
当前线程不是 VM_thread,调用 wait_until_executed 等待任务执行完成。关于 VMThread 任务模型可以看 VMThread 任务模型。
void VMThread::execute(VM_Operation* op) {
Thread* t = Thread::current();
if (t->is_VM_thread()) {
op->set_calling_thread(t);
((VMThread*)t)->inner_execute(op);
return;
}
op->set_calling_thread(t);
wait_until_executed(op);
op->doit_epilogue();
}
VM_G1CollectForAllocation 将 GC 和分配逻辑进行封装。
g1h->do_collection_pause_at_safepoint() 首先进行 partial GC 也就是 Young GC,包含 Young only gc 和 mixed GC。
satisfy_failed_allocation 先进行内存分配,失败时则执行 full GC。
当 _word_size <= 0 时直接执行 g1h->upgrade_to_full_collection() Full GC。
void VM_G1CollectForAllocation::doit() {
G1CollectedHeap* g1h = G1CollectedHeap::heap();
GCCauseSetter x(g1h, _gc_cause);
// Try a partial collection of some kind
_gc_succeeded = g1h->do_collection_pause_at_safepoint();
if (_word_size > 0) {
_result = g1h->satisfy_failed_allocation(_word_size, &_gc_succeeded);
} else if (g1h->should_upgrade_to_full_gc()) {
_gc_succeeded = g1h->upgrade_to_full_collection();
}
}
到此为止,对象内存分配已经讲完了,obj 是指向新对象的指针。
instanceOop InstanceKlass::allocate_instance(TRAPS) {
size_t size = size_helper(); // Query before forming handle.
return (instanceOop)Universe::heap()->obj_allocate(this, size, CHECK_NULL);
}
class instanceOopDesc : public oopDesc {
};
JRT_ENTRY(void, InterpreterRuntime::_new(JavaThread* current, ConstantPool* pool, int index))
oop obj = klass->allocate_instance(CHECK);
current->set_vm_result(obj);
JRT_END
执行构造方法
前文分配拿到的对象只是初始化了对象头,而没有初始化实例数据的对象,需要调用构造方法执行对象初始化。以 ObjNewTest 类为例讲解构造方法的执行流程。
public class ObjNewTest {
public static ObjNewTest getInstance() {
return new ObjNewTest();
}
}
下面是对应字节码文件。new 指令在前文中已经讲解了,dup 指令复制栈顶元素并且加入到栈中。
invokespecial 指令是弹出栈顶元素,并且执行构造方法。
areturn 返回栈顶元素,也就是对象引用。
#7 = Class #8 // test/java/ObjNewTest
#8 = Utf8 test/java/ObjNewTest
#9 = Methodref #7.#3 // test/java/ObjNewTest."<init>":()V
{
public test.java.ObjNewTest();
descriptor: ()V
flags: (0x0001) ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 4: 0
public static test.java.ObjNewTest getInstance();
descriptor: ()Ltest/java/ObjNewTest;
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=0, args_size=0
0: new #7 // class test/java/ObjNewTest
3: dup
4: invokespecial #9 // Method "<init>":()V
7: areturn
LineNumberTable:
line 14: 0
}
SourceFile: "ObjNewTest.java"
本节关注 invokespecial #9 如何执行。
_invokespecial 执行入口
CASE(_invokevirtual):
CASE(_invokespecial):
CASE(_invokestatic): {
u2 index = Bytes::get_native_u2(pc+1);
ResolvedMethodEntry* entry = cp->resolved_method_entry_at(index)
if ((Bytecodes::Code)opcode == Bytecodes::_invokespecial) {
CHECK_NULL(STACK_OBJECT(-(entry->number_of_parameters())));
}
callee = entry->method();
istate->set_callee(callee);
istate->set_callee_entry_point(callee->from_interpreted_entry());
}
pc+1使用 get_native_u2 读取两个字节整数,9 是常量池中的索引,即下面的方法引用。
#9 = Methodref #7.#3 // test/java/ObjNewTest."<init>":()V
cp->resolved_method_entry_at 根据索引从常量池找到对应方法。
inline ResolvedMethodEntry* ConstantPoolCache::resolved_method_entry_at(int method_index) const {
return _resolved_method_entries->adr_at(method_index);
}
下面设置解释器要执行的方法,并开始执行代码。
istate->set_callee(callee);
istate->set_callee_entry_point(callee->from_interpreted_entry());
UPDATE_PC_AND_RETURN(0)
public test.java.ObjNewTest();
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
至此对象创建完成。
总结
对象的创建是 JVM 的核心功能之一,它贯穿了字节码指令解析、类加载、内存分配以及构造方法调用等多个环节。通过分析源码可以看出:
JVM 在解析 new 指令时,首先通过常量池查找到对应的 Klass 实例。 类加载器负责解析 .class 文件并创建 InstanceKlass 对象,其中涉及字节码解析和类结构的构建。 内存分配是对象创建的关键步骤,JVM 使用多种策略管理堆内存,特别是对于大对象,G1 收集器通过区域分配的方式提高了内存利用率。 构造方法的调用是对象初始化的最后一步,通过 invokespecial 指令完成。
通过本文的解析,开发者可以更好地理解 Java 对象的创建过程,深入掌握 JVM 的内存管理机制和类加载器的实现原理,为日常开发和性能调优提供理论支持。
本文对于方法的调用和执行解释不足,是后文写作的内容。